OpsGuide/Planning for deploying and provisioning OpenStack
The decisions you make with respect to provisioning and deployment will affect your maintenance of the cloud. Your configuration management will be able to evolve over time. However, more thought and design need to be done for upfront choices about deployment, disk partitioning, and network configuration.
A critical part of a cloud’s scalability is the amount of effort that it takes to run your cloud. To minimize the operational cost of running your cloud, set up and use an automated deployment and configuration infrastructure with a configuration management system, such as Puppet or Chef. Combined, these systems greatly reduce manual effort and the chance for operator error.
This infrastructure includes systems to automatically install the operating system’s initial configuration and later coordinate the configuration of all services automatically and centrally, which reduces both manual effort and the chance for error. Examples include Ansible, CFEngine, Chef, Puppet, and Salt. You can even use OpenStack to deploy OpenStack, named TripleO (OpenStack On OpenStack).
Contents
Automated deployment
An automated deployment system installs and configures operating systems on new servers, without intervention, after the absolute minimum amount of manual work, including physical racking, MAC-to-IP assignment, and power configuration. Typically, solutions rely on wrappers around PXE boot and TFTP servers for the basic operating system install and then hand off to an automated configuration management system.
Both Ubuntu and Red Hat Enterprise Linux include mechanisms for configuring the operating system, including preseed and kickstart, that you can use after a network boot. Typically, these are used to bootstrap an automated configuration system. Alternatively, you can use an image-based approach for deploying the operating system, such as systemimager. You can use both approaches with a virtualized infrastructure, such as when you run VMs to separate your control services and physical infrastructure.
When you create a deployment plan, focus on a few vital areas because they are very hard to modify post deployment. The next two sections talk about configurations for:
- Disk partitioning and disk array setup for scalability
- Networking configuration just for PXE booting
Disk partitioning and RAID
At the very base of any operating system are the hard drives on which the operating system (OS) is installed.
You must complete the following configurations on the server’s hard drives:
- Partitioning, which provides greater flexibility for layout of operating system and swap space, as described below.
- Adding to a RAID array (RAID stands for redundant array of independent disks), based on the number of disks you have available, so that you can add capacity as your cloud grows. Some options are described in more detail below.
The simplest option to get started is to use one hard drive with two partitions:
- File system to store files and directories, where all the data lives, including the root partition that starts and runs the system.
- Swap space to free up memory for processes, as an independent area of the physical disk used only for swapping and nothing else.
RAID is not used in this simplistic one-drive setup because generally for production clouds, you want to ensure that if one disk fails, another can take its place. Instead, for production, use more than one disk. The number of disks determine what types of RAID arrays to build.
We recommend that you choose one of the following multiple disk options:
- Option 1
Partition all drives in the same way in a horizontal fashion, as shown in Partition setup of drives.
With this option, you can assign different partitions to different RAID arrays. You can allocate partition 1 of disk one and two to the
/bootpartition mirror. You can make partition 2 of all disks the root partition mirror. You can use partition 3 of all disks for acinder-volumesLVM partition running on a RAID 10 array.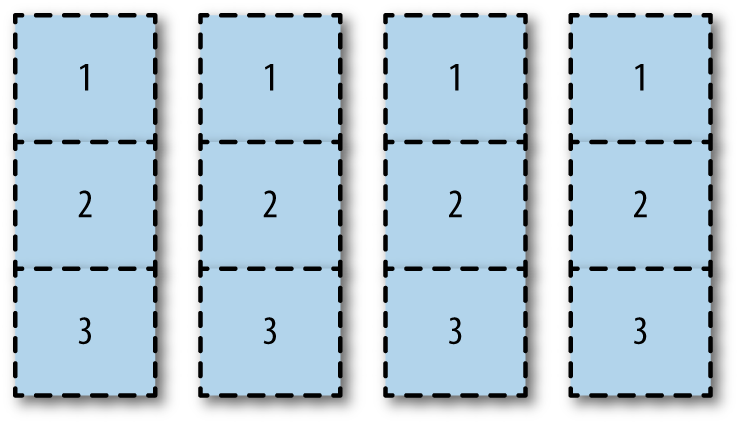 Partition setup of drives
Partition setup of drivesWhile you might end up with unused partitions, such as partition 1 in disk three and four of this example, this option allows for maximum utilization of disk space. I/O performance might be an issue as a result of all disks being used for all tasks.
- Option 2
- Add all raw disks to one large RAID array, either hardware or software based. You can partition this large array with the boot, root, swap, and LVM areas. This option is simple to implement and uses all partitions. However, disk I/O might suffer.
- Option 3
- Dedicate entire disks to certain partitions. For example, you could allocate disk one and two entirely to the boot, root, and swap partitions under a RAID 1 mirror. Then, allocate disk three and four entirely to the LVM partition, also under a RAID 1 mirror. Disk I/O should be better because I/O is focused on dedicated tasks. However, the LVM partition is much smaller.

You may find that you can automate the partitioning itself. For example, MIT uses Fully Automatic Installation (FAI) to do the initial PXE-based partition and then install using a combination of min/max and percentage-based partitioning.
As with most architecture choices, the right answer depends on your environment. If you are using existing hardware, you know the disk density of your servers and can determine some decisions based on the options above. If you are going through a procurement process, your user’s requirements also help you determine hardware purchases. Here are some examples from a private cloud providing web developers custom environments at AT&T. This example is from a specific deployment, so your existing hardware or procurement opportunity may vary from this. AT&T uses three types of hardware in its deployment:
- Hardware for controller nodes, used for all stateless OpenStack API services. About 32–64 GB memory, small attached disk, one processor, varied number of cores, such as 6–12.
- Hardware for compute nodes. Typically 256 or 144 GB memory, two processors, 24 cores. 4–6 TB direct attached storage, typically in a RAID 5 configuration.
- Hardware for storage nodes. Typically for these, the disk space is optimized for the lowest cost per GB of storage while maintaining rack-space efficiency.
Again, the right answer depends on your environment. You have to make your decision based on the trade-offs between space utilization, simplicity, and I/O performance.
Network configuration
Network configuration is a very large topic that spans multiple areas of this book. For now, make sure that your servers can PXE boot and successfully communicate with the deployment server.
For example, you usually cannot configure NICs for VLANs when PXE booting. Additionally, you usually cannot PXE boot with bonded NICs. If you run into this scenario, consider using a simple 1 GB switch in a private network on which only your cloud communicates.
Automated configuration
The purpose of automatic configuration management is to establish and maintain the consistency of a system without using human intervention. You want to maintain consistency in your deployments so that you can have the same cloud every time, repeatably. Proper use of automatic configuration-management tools ensures that components of the cloud systems are in particular states, in addition to simplifying deployment, and configuration change propagation.
These tools also make it possible to test and roll back changes, as they are fully repeatable. Conveniently, a large body of work has been done by the OpenStack community in this space. Puppet, a configuration management tool, even provides official modules for OpenStack projects in an OpenStack infrastructure system known as Puppet OpenStack. Chef configuration management is provided within https://git.openstack.org/cgit/openstack/openstack-chef-repo. Additional configuration management systems include Juju, Ansible, and Salt. Also, PackStack is a command-line utility for Red Hat Enterprise Linux and derivatives that uses Puppet modules to support rapid deployment of OpenStack on existing servers over an SSH connection.
An integral part of a configuration-management system is the item that it controls. You should carefully consider all of the items that you want, or do not want, to be automatically managed. For example, you may not want to automatically format hard drives with user data.
Remote management
In our experience, most operators don’t sit right next to the servers running the cloud, and many don’t necessarily enjoy visiting the data center. OpenStack should be entirely remotely configurable, but sometimes not everything goes according to plan.
In this instance, having an out-of-band access into nodes running OpenStack components is a boon. The IPMI protocol is the de facto standard here, and acquiring hardware that supports it is highly recommended to achieve that lights-out data center aim.
In addition, consider remote power control as well. While IPMI usually controls the server’s power state, having remote access to the PDU that the server is plugged into can really be useful for situations when everything seems wedged.
Other considerations
You can save time by understanding the use cases for the cloud you want to create. Use cases for OpenStack are varied. Some include object storage only; others require preconfigured compute resources to speed development-environment set up; and others need fast provisioning of compute resources that are already secured per tenant with private networks. Your users may have need for highly redundant servers to make sure their legacy applications continue to run. Perhaps a goal would be to architect these legacy applications so that they run on multiple instances in a cloudy, fault-tolerant way, but not make it a goal to add to those clusters over time. Your users may indicate that they need scaling considerations because of heavy Windows server use.
You can save resources by looking at the best fit for the hardware you have in place already. You might have some high-density storage hardware available. You could format and repurpose those servers for OpenStack Object Storage. All of these considerations and input from users help you build your use case and your deployment plan.
For further research about OpenStack deployment, investigate the supported and documented preconfigured, prepackaged installers for OpenStack from companies such as Canonical, Cisco, Cloudscaling, IBM, Metacloud, Mirantis, Rackspace, Red Hat, SUSE, and SwiftStack.