User talk:Fengqian
Contents
Why and how to use Intel Node Manager in Openstack
This Wiki is used to show how we can use Intel Node Manager in Openstack.
First, it will give a brief introduction to Intel Node Manager; then it will describe how we can leverage these features in Openstack.
Introduction of Node Manager
Intel Node Manager is a server management technology that allows management software to accurately monitor and control the platform’s power and thermal behaviors through industry defined standards: Intelligent Platform Management Interface(IPMI) and Datacenter Manageability Interface (DCMI).
It allows the administrator of IT to monitor the power and thermal behaviors of servers and make reasonable operation or policy according to the real-time power/thermal status of data center. Using Intel Node Manager,the power and thermal information of these servers can be used to improve overall data center efficiency and maximize overall data center usage. Data center managers can maximize the rack density with the confidence that rack power budget will not be exceeded. During a power or thermal emergency, Intel Node Manager can automatically limit server power consumption and send alert to administrators via the pre-defined policy.
The main features of Intel Node Manager can be described as following.
1) Monitor power/temperature.(Trying to implemented in Openstack and patches are ready, please see the following link in next section)
- Collect the power/thermal information via IPMI command. It also can collect data of each subsystem, such as CPU, Memory or I/O.
2) Make policy based on power/thermal.(It is not be implemented yet. You can use the 3rd party software or Intel software to do the policy stuffs)
- Pre-defined policy can be made based on power/thermal data.
- We can set power budget for the server, if power exceeds the threshold, frequency of CPU will decrease to bring power consumption down. (It is also called "Power Capping").
- Policy also can be made for the power/thermal emergency, if the data exceed threshold, the pre-defined operation will executed, such as shut down server or decrease CPU frequency or send alert, etc.
How to use Node Manager in Openstack
Nova
One of reasonable usage of Node Manager in Openstack is for Nova, nova-scheduler. For now, nova collects some information for scheduler, CPU/Memory. But that may be not enough. Power/temperature can also be used to describe the status of a compute node and Filter/Weight can be made according to the power/temperature information.
For example, when scheduler need to choose one compute node to launch new instance and the power of the nodes are collected as 100Watts, 120Watts and 150Watts. To balance the power consumption of all nodes, a filter can be made to remove the node with highest power; or to save power, remove the lowest node. That depends on users.
- Example of filter/weight
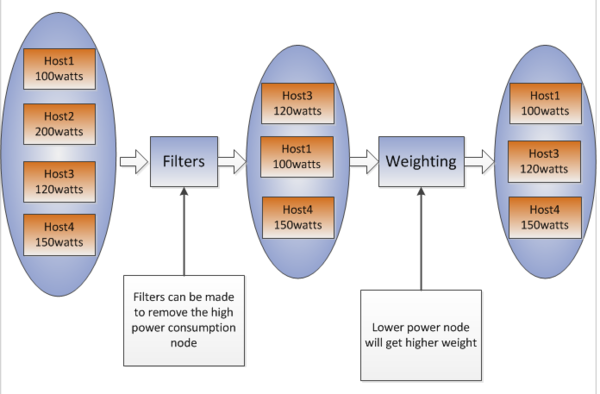

Another example is that users can set the power threshold for the servers in the data center, 200Watts, for example, then the power consumption higher than 200 is filtered when scheduler choose the available nodes.
Weight can be made for the scheduler via power information. To balance power consumption, higher power node gets lower weight, or higher power node gets higher weight to save power.
The temperature information can be used for the scheduler in the same manner.
To enable above described usage, we can add node manager monitors in nova-compute. We call IPMI command locally to get power and temperature. Here are the patches.
Add node manager to read power/temperature of compute node
Added temperature monitor for compute node
Added power monitor for compute node
ceilometer
Another usage is for ceilometer. Power/temperature status of servers or whole data center can be finding out in ceilometer. (More details is needed)
Policy can be made ad load from configure file(Just take an example, other solutions can be provide either) and threshold/operations can be set. When the power/temperature exceed the threshold, alert message will be send out and showed in the UI of ceilometer or dashboard. Pre-defined operation will be adopted also.
Pagination DB search
This wiki is used for the design notes of openstack blueprint pagination_db_search. The mainly idea of pagination is retrieve from openstack manuals. You may see this link for details.
http://docs.openstack.org/api/openstack-network/2.0/content/pagination.html
Detils
We use “limit+marker” to paginate the db query results, while the marker parameter is the ID of the last item in the previous list and the limit parameter sets the page size.
The reason that use “limit+marker”is it can provide better performance than “limit+offset”. In some other modules of openstack, same solution is implemented already, such as glance. But different from the manuals, we provide more parameters here.
Sort_keys and sort_dirs allow users to specify their own sort keys and directions.
As to primary_sort_dir, each database table should have a primary key that can identify a unique object by one value, it refers to the sort directions of this key.
About the marker/sort_keys/sort_dirs:
Here, I would like to quote from the mail from Jay Pipes. It shows why and how to use marker/sort_keys/sort_dirs.( Thanks, Jay, you help me a lot here:) )
You first sort by the keys provided by the user, and then after those keys, you always sort by the marker column, which should always be the primary key column(s). To demonstrate why this is so, assume the following table structure and values:
CREATE TABLE t1 ( id INT NOT NULL PRIMARY KEY, created_at DATE NOT NULL, a VARCHAR(10) NULL, INDEX (created_at) ); INSERT INTO t1 VALUES (1, '2013-09-03', 'aaa'), (2, '2013-09-06', 'bbb'), (3, '2013-09-03', 'ccc'), (4, '2013-09-03', 'bbb'), (5, '2013-09-06', 'aaa'), (6, '2013-09-06', NULL);
Scenario: User (or perhaps the default sort order) wants to sort by created_at DESC. If we sorted on the marker first, and then the user-supplied sort key, the first page would be: SELECT * FROM t1 ORDER BY id ASC, created_at DESC LIMIT 2;
The results would be:
+----+------------+------+ | id | created_at | a | +----+------------+------+ | 1 | 2013-09-03 | aaa | | 2 | 2013-09-06 | bbb | +----+------------+------+ But that is incorrect. The user asked for the latest records (created_at DESC), and those two records are not the latest ones by date. Instead, we need to first sort by the user-provided sort key and then the marker column (id):
SELECT * FROM t1 ORDER BY created_at DESC, id ASC LIMIT 2; +----+------------+------+ | id | created_at | a | +----+------------+------+ | 2 | 2013-09-06 | bbb | | 5 | 2013-09-06 | aaa | +----+------------+------+
Note that there are actually 3 records with created_at == 2013-09-06, but since the page size is 2, we only got the records with id of 2 and 5. If we had not specified the id ASC in the ORDER BY, then the results would be non-deterministic. Now, to get the second page of results for the same scenario, we need to apply a filter, like so:
SELECT * FROM t1 WHERE created_at < '2013-09-06' OR (created_at = '2013-09-06' AND id > 5) ORDER BY created_at DESC, id ASC LIMIT 2; +----+------------+------+ | id | created_at | a | +----+------------+------+ | 6 | 2013-09-06 | NULL | | 1 | 2013-09-03 | aaa | +----+------------+------+
So, Fengqian is correct to query the database to retrieve the record associated with that primary key marker value... EXCEPT in one case :) When the sort key specified (either by the user or as the default sort key) is the primary key, then there's no need to look up the marker record in full.
It's easiest to see in SQL code and results.
To get the first page of results when ordering by id (primary key): SELECT * FROM t1 ORDER BY id ASC LIMIT 2; +----+------------+------+ | id | created_at | a | +----+------------+------+ | 1 | 2013-09-03 | aaa | | 2 | 2013-09-06 | bbb | +----+------------+------+
Presuming that the only thing the caller supplies when grabbing the next page is the id of 2, then the next page would be queried like so: SELECT * FROM t1 WHERE id > 2 ORDER BY id ASC LIMIT 2; +----+------------+------+ | id | created_at | a | +----+------------+------ | 3 | 2013-09-03 | ccc | | 4 | 2013-09-03 | bbb | +----+------------+------+
So, in short, if Fengqian adds in a quick short-circuit check that simply uses the marker value for the search criteria when the only sort key is the primary key, I'd be good with the patch.
About the TRANSLATE_KEYS:
Ceilometer supports multiple database, but for different database, they may have different key name.
For example alarm_id is used in Mongodb while sqlalchemy use id. From API level, we provide a common interface, so we need to transfer the key for different database.
In all, to implemented pagination, we add few parameters here, marker/limit/primary_sort_dir/sort_keys/sort_dirs and put them in a class named Pagination.
Default primary_key and its sort direction is provided in each database model. Besides that, user can input their own sort keys and sort directions.