Difference between revisions of "UnifiedInstrumentationMetering"
| Line 1: | Line 1: | ||
| − | |||
= Unified Instrumentation and Metering = | = Unified Instrumentation and Metering = | ||
Last edit: -- [[SandyWalsh]] | Last edit: -- [[SandyWalsh]] | ||
| − | |||
== Overview == | == Overview == | ||
Revision as of 22:03, 16 February 2013
Contents
Unified Instrumentation and Metering
Last edit: -- SandyWalsh
Overview
With Ceilometer, Tach and [[StackTach]], there are some very cool initiatives going on around instrumentation and metering/monitoring within OpenStack today.
However, due to the incredible speed of development within OpenStack many of these efforts have been performed in isolation from each other. Now, we are reaching a level of maturity which demands we stop reinventing the wheel and agree upon some shared infrastructure. This need is necessary for a variety of reasons:
- We want to make it easier for new projects to build on the existing OpenStack notification message bus.
- Less code is good. We shouldn't need three different workers for extracting notifications from OpenStack.
- Notifications are large and there's a lot of them. We only want to process and store that data once.
- Archiving of data is a common problem, we shouldn't need several different ways of doing it.
In this document we'll talk about the State-of-Art with respect to Instrumentation/Metering/Monitoring (IMM) with OpenStack today and where we might go with it.
Required reading / viewing:
- http://www.openstack.org/summit/san-diego-2012/openstack-summit-sessions/presentation/what-about-billing-an-introduction-to-ceilometer
- http://www.sandywalsh.com/2012/10/debugging-openstack-with-stacktach-and.html
- https://etherpad.openstack.org/grizzly-common-instrumentation (good summary of instrumentation needs)
Instrumentation vs Metering/Monitoring
At the very base of this discussion is having a clear understanding of the difference between Instrumentation and Metering/Monitoring.
Instrumentation
Think of instrumentation as the way they test electronics in-circuit. While the device is running, probes are attached to the circuit board and measurements are taken.

There are some key things to consider in this analogy:
- Every technician may want to place their probes in different locations.
- Probes might be placed for long term measuring or transient ("I wonder if ... " scenarios)
- The circuit does not have to change for the testing probes to be placed. No other groups or departments had to be involved for this instrumentation to occur.
- The same probe technology can be used on other circuit boards. Likewise, our instrumentation probe-placement technology should not just be geared towards Nova. It should also work with all other parts of OpenStack.
- When the circuit changes our probe placement may have to change. We have to be aware of that.
- The probes aren't perfect. They might slip off or have a spotty connection. We're looking for trends here, identifying when things are slow or flaky.
- With respect to Python, we may be interested in stack traces as well. Not just single function timings/counts.
Metering / Monitoring
Metering is watching usage of the system, usually for the purposes of Billing. Monitoring is watching the system for critical system changes, performance and accuracy, usually for things like SLA's.
Think of your power meter. You can go outside and watch the dial spin and confirm your monthly bill jives with what the meter is reporting.

The important aspects of metering and monitoring:
- These events/measurements are critical. We cannot risk dropping an event.
- We need to ensure these events are consistent between releases. Their consistency should be considered of equal importance as OpenStack API consistency.
- We have no idea how people are going to want to use these events, but we can safely assume there will be a lots of other groups interested in them. We don't want these groups talking to the production OpenStack deployments directly.
- These events may not be nearly as frequent as the instrumentation messages, but they will be a lot larger since the entire context of the message needs to be included (which instance, which image, which user, etc)
The State-of-the-Art
So, where are we?
Instrumentation Today
There is no formal instrumentation solution for OpenStack today (other than logging). Logging is insufficient because it's:
- unstructured text
- too much effort to scan, parse and correlate across servers
- requires code changes to collect new information
Rackspace has being using a cocktail of Tach, Statsd, Graphite and Nagios to great success for close to a year.

Tach is a library that collects timing/count data from anywhere in a Python program. It's not specific to OpenStack, but it has pre-canned config files for the main OpenStack services. Tach hooks into a programming using monkey-patching and has a concept of Metrics and Notifiers. The Metrics are user-extensible hooks that pull data from the code. The Notifiers take the collected data and send it somewhere. Currently there are Metrics drivers for execution time and counts as well as Notifiers for Statsd, Graphite directly, print and log files. (SandyWalsh has been working on a replacement for Tach, called Scrutinize which adds cProfile support and easier configuration. It's almost ready for prime-time.)
Tach is launched as: tach tach.conf nova-compute nova.conf ... so it easily integrates with existing deployments.
The powerful features of statsd are:
- UDP based messaging, so production is not at risk if the collectors die.
- In-memory rollup/aggregate of measurements that get relayed to Graphite. This greatly enhances scalability.
- Written in node.js = fast, fast, fast.
Monitoring/Metering Today
Certainly the face of Monitoring and Metering within OpenStack today is Ceilometer ... I'll just refer you to that project for more details.
But there are others. Within Rackspace we use YAGI to consume the notifications and send them to our internal billing system. Specifically, this data is sent to AtomHopper where it is turned into an Atom feed for other consumers (one of which is billing). YAGI used to have PubSubHubBub support, but that's gone dormant due to other motivators. Now, AtomHopper is the redistribution system of choice. Sadly, AtomHopper is Java-based, so it may not work well within the OpenStack ecosystem, per se. The YAGI Worker uses carrot and has been highly reliable in all of our environments, but there has been discussion of moving to kombu.
StackTach is a debugging/monitoring tool based on OpenStack notifications and it too has its own Worker. It is kombu-based and is currently used in production. We've had lots of problems making the stacktach worker reliable but we think the problem has been with combining a threading model with eventlet. Our new scheme uses the multiprocessing library with per-rabbit workers. This is currently being stress tested, stay tuned. We've tried a variety of other schemes and library combinations with little success (more detail if needed). Note: this should work fine since it's the same scheme Nova uses internally.
StackTach is quickly moving into Metrics, SLA and Monitoring territory with version 2 and the inclusion of Stacky (the command line interface to StackTach)
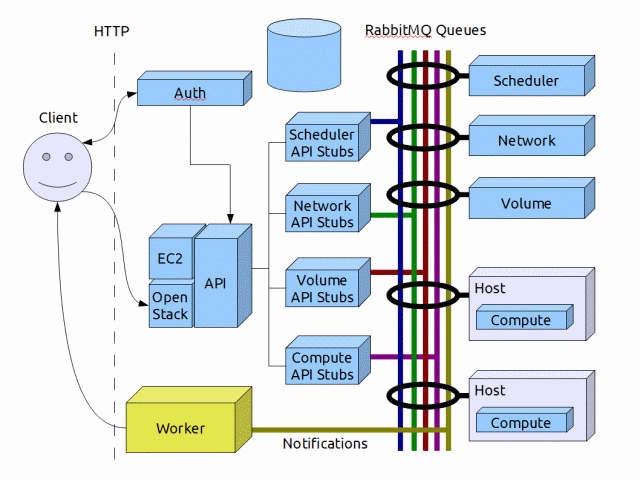

The Layers
With every architecture there are different layers of abstraction/functionality.
IMM has:
- low-level components that directly interface with OpenStack via monkeypatching or notification consumption.
- mid-level components that collect, aggregate and redistribute this collected data to other consumers
- high-level components that act as the presentation layer.
We currently have overlap on all levels.

Unifying the Low Level
There is really no way to unify the instrumentation collection with the metrics collection infrastructure within OpenStack. As stated in the introduction, these are very different animals.
With respect to Monitoring and Metering (notification consumption), the obvious candidate is the notification worker. Using a list of queues in the rabbit notifier is not a solution, it's a big load on the rabbit server.
Note: we're also using AMQP incorrectly for notifications. Events are published to an Exchange and different queues can be created for different consumers. Currently, OpenStack creates a different Exchange for each notification destination. This should simply a bug that should be fixed.
This is the low-hanging fruit. Creating a scalable worker that can work in a multi-rabbit (multi-cell, mult-region) deployment. It should support a pluggable scheme for handling the collected data and support failover/redundancy. The worker has to be fast/reliable enough to keep the notification queue empty since this is easily the fastest growing queue (neck and neck with the cells capacity update queue :)
The worker should be a separate repository so others can use it standalone.
Also, the Ceilometer worker doesn't need to use all of the nova-common code. This is very simple program and can be handled with a single file.
Unifying the Mid-Level
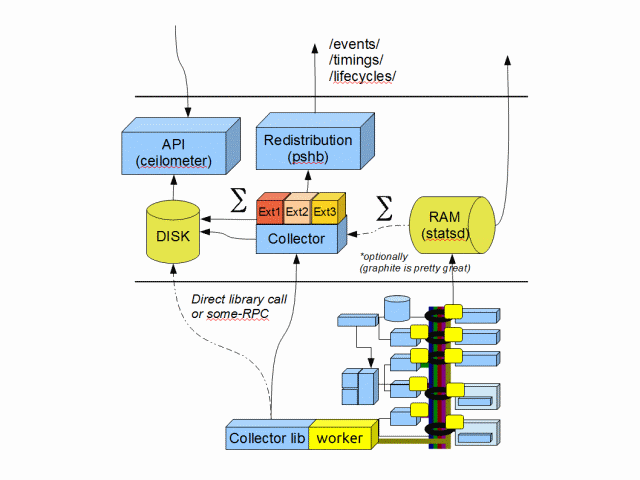

A Common Database for Collected Data
For metering and monitoring, both StackTach and Ceilometer have a database to store the notifications. StackTach uses a SQL-based database, while Ceilometer uses a key-value database (Mongo). Each notification is large and contains about ten columns that are required to have fast lookup:
- Deployment ID
- Tenant ID
- UUID
- Request ID
- Timestamp
- Instance State
- Instance Task
- Publisher
- Host ID
- Event name
Additionally the entire JSON payload should be stored for the event for consumers that need something specific.
I have no recommendation on which db to use, but perhaps some load testing should be performed to see how well each works. The important thing is, the entire event gets stored.
However, as these events get collected, there are often additional tables that need to get updated which contain aggregated/summarized information from the events. While these operations could be done in a batch fashion in a separate database it's likely more efficient to provide a means for other applications to hook into the data collection and update these tables in real-time. This is what StackTach does and it greatly reduces the post-processing required. It does, however, come at a cost of additional processing when event storage is being performed (an expensive operation). Something like Ceilometer's secondary publishing step seems a good solution here, but I think it should be based on an AtomHopper/PSHB approach vs something proprietary. We should discuss what redistribution system looks like in greater detail.
In the diagram above Ext1, Ext2, Ext3 are user-plugins for doing special aggregation work. (not for sending to the redistribution system, another plugin mechanism could handle that)
For instrumentation, as mentioned above, the statsd in-memory database is a perfect solution here. Probably not much to improve on here.
A Common Event Redistribution System
As mentioned earlier, we use AtomHopper internally (and YAGI w/PSHB previously), but it would be nice to use an off-the-shelf framework, ideally something Python-based. This too should be a separate repo and, ideally, optional.
In the DreamHost use case, The Dude should consume from the AtomHopper feed based on webhooks vs. having to poll the Ceilometer API for updates.
Alerts / Set Points / Thresholds
Personally, I don't think this belongs in the Middle Layer ... external components should define/monitor/control these.
Unifying the Top Layer
Every client is different, trying to service the needs of each user with a common user interface might be tricky. StackTach started as a debugging tool and targets that audience. A Billing tool will need a very different UI.
There are lots of off-the-shelf products available for the presentation of instrumentation data, we shouldn't need to reinvent that wheel.
StackTach and Stacky should both consume from the Ceilometer API.
Other Improvements
- Remove the Compute service that Ceilometer uses and integrate the existing fanout compute notifications into the data collected by the workers. There's no need for yet-another-worker. That said, I'm sure there are specific things that certain deployments will need that aren't covered by this and the existing Ceilometer collector system will still be needed.
- StackTach has taken major steps in optimizing its REST interface to facilitate caching. The data in the middle layer is largely read-only and there are far more readers than writers. The Ceilometer API should consider these improvements (if it's not dealt with already and I missed it)