Raksha
Contents
OpenStack Data Protection As Service("Raksha")
| [Raksha on launchpad (including bug tracker and blueprints)] |
| [Raksha Source] |
Related projects
- Python Raksha client
- Raksha API documentation
What is Raksha?
Raksha is a scalable data protection service for OpenStack cloud without the burden of handling complex administrative tasks associated with setting up backup products. OpenStack tenants can choose backup policies for their workloads and the Raksha service leverages existing hooks in Nova and Cinder to provide data protection services to tenants. The goal of this service is to provide data protection to OpenStack cloud, while automating data protection tasks including consistent snap of resources, creating space efficient data streams for snapped resources and streaming the backup data to swift end points. Just like any other service in OpenStack, Data Protection as a Service is consumed by tenants; hence, Horizon dashboard will be enhanced to support data protection service.
Rationale
Over the last three years OpenStack has experienced tremendous growth in terms of its maturity as cloud platform and has been evolving into platform of choice for public and private clouds. As with any cloud platform, OpenStack also needs a reliable data protection service.
Currently the following APIs are available to build a data protection solution for OpenStack.
- Nova - Instance Snapshot: Backup the root volume to Glance
- Cinder - Volume Snapshot: Snapshot volumes
- Cinder - Volume Backup: Backup volumes to Swift
Nova has image snapshot API that will enable tenant to take a live backup of the boot volume. Cinder has defined volume backup and restore APIs, and storage vendors are supporting these APIs for their products. Though these features are extremely useful in implementing a total backup solution, there are some gaps.
For example, the current volume backup APIs require the entire volume to be backed up. The volumes tend to grow upward of tens to hundreds of Gigabytes. Though current backup APIs support compression, depending on the size of the data set, it can still incur considerable data transfer. Moreover the compression of the entire volume does not remove the need to read the entire volume, which adds additional strain on the storage. A better answer would be to track changed blocks since last the backup and stream only changed blocks to the backup service end point.
Another feature that is required is the application consistent backup. An application can consist of one or more VMs and each VM may have one or more volumes. In order to take an application consistent backup, a higher order function that identifies the VMs of the application and their resources, and then take a consistent snap of resources. Application consistency is an essential feature to have a reliable restart-able backup image.
The current implementation of backup APIs is complex. Nova and Cinder use different services to stream the backup images where Nova uses Glance and Cinder uses Swift.
Also backup APIs are distributed across multiple projects and have been evolving independent of each other.
For any seamless backup solution, one needs the following:
- Non-disruptive backup of VM images
- Smaller backup and restore windows
- Efficient data transfers of backup images to service end points. For example dedupe/change block tracking at the source reduces the amount of data transfer.
- Application consistent backups
- Scheduler for periodic backups
To consolidate and fill the gaps in the current data protection mecahnisms, we propose a new project called Raksha ( Sanskrit, meaning: ‘protection’), a Data Protection as a Service for OpenStack. Raksha is a standalone project and once it is accepted as a core project of OpenStack, it offers an out-of-box and ready-to-deploy data protection solution for OpenStack.
Raksha Overview
Raksha provides a comprehensive Data Protection for OpenStack by leveraging Nova, Swift, Glance and Cinder. Raksha has the following primary goals:
- Provide VM(s) centric data protection service.
- Application consistent backups
- Dedupe/change block tracking at the source for efficient backups
- Point-In-Time backup copies
- A job scheduler for periodic backups
- Noninvasive backup solution that does not require service interruption during backup window
- Tenant administered backups and restore
VM Backup
- Backup of Boot Image(Volume) - an instance can boot from an image or snapshot
- Full
- Backup to a swift end point
- Metadata contains a reference to the original Image ( or Cinder Volume in case of boot from volume)
- Incremental
- New changes (since the last backup) are uploaded to a swift end point
- Full
- Backup of attached volume(s)
- Full
- Backup to a swift end point
- Metadata contains a reference to the original Volume
- Incremental
- New changes (since the last backup) are uploaded to a swift end point
- Full

VM Restore
- Boot Image/Volume Restore
- Restore Image
- If base is not available in Glance: Create a new image with a flattened “full backup of base image + incremental backups”. ( another choice is to restore ‘base image’ and ‘flattened incremental backups’ as separate images)
- If base is available in Glance: Create a new image using ‘flattened incremental backups’ with a reference to base image.
- Restore Volume
- Create a new volume with a flattened “full backup of base volume + incremental backups”.
- Restore Image
- Restore Volume(s) that are not boot devices
- Create a new volume with a flattened “full backup of base volume+ incremental backups”.


Assumptions
Design
The following is the architecture diagram of Raksha.
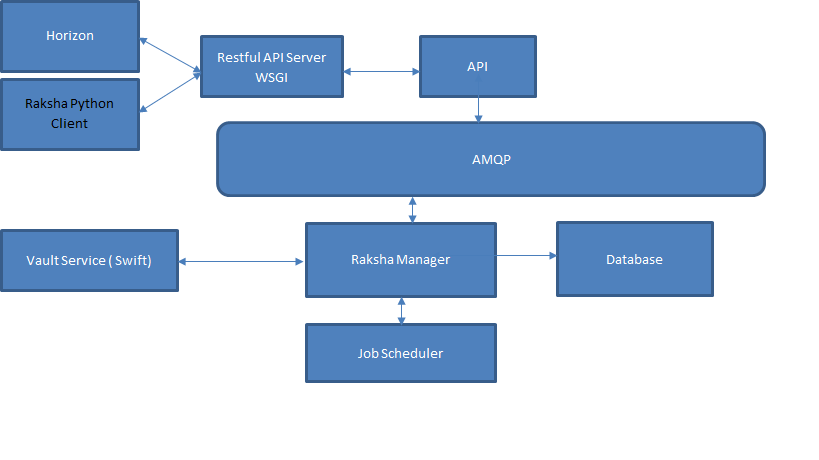
Similar to other OpenStack projects Raksha provides an API, CLI and Dashboard integration.
Database
We will use the same persistent layer as other OpenStack projects: mysql database to persist Raksha data.

APIs
| API | DESCRIPTION | VERB | URI |
|---|---|---|---|
| List | List of backupjobs accessible to the tenant who submits the request | GET | v1/{tenant_id}/backupjobs |
| Show | List detailed information for the specified backupjob | GET | v1/{tenant_id}/backupjobs/backupjob_id |
| Create | Create a new backupjob | POST | v1/{tenant_id}/backupjobs |
| Update | Update a backup job | PUT | v1/{tenant_id}/backupjobs/backupjob_id |
| Delete | Delete a backup job | DELETE | v1/{tenant_id}/backupjobs/backupjob_id |
| Full Backup | Run a full backup job | POST | v1/{tenant_id}/backupjobs/backupjob_id/full |
| Incremental Backup | Run an incremental backup job | POST | v1/{tenant_id}/backupjobs/backupjob_id/incremental |
| List Runs | List of backup job runs of a given backup job id | GET | v1/{tenant_id}/ backupjobs/backupjob_id/backupjobsruns |
| Show Run | Show detail description of given backup job run | GET | v1/{tenant_id}/backupjobs/backupjob_id/backupjobsruns/backupjobrun_id |
| Run Backup Job Once | Run a backup job once | POST | v1/{tenant_id}/backupjobs/backupjob_id/backupjobsruns |
| Update Backup Job Run | Update the description of a given backup job run | PUT | v1/{tenant_id}/backupjobs/backupjob_id/backupjobsruns/backupjobrun_id |
| Delete Backup Job Run | Delete a given backup job run | DELETE | v1/{tenant_id}/backupjobs/backupjob_id/backupjobsruns/backupjobrun_id |
| Restore from Backup Job Run | Restore a given backup job run | POST | v1/{tenant_id}/backupjobs/backupjob_id/backupjobsruns/backupjobrun_id |
Job Scheduler
We will explore new openstack project tasklist for scheduling backup jobs
Vault Service
A vault service provides a location for storing the backups. The default implementation of Raksha uses the swift store for storing backup images. All backup images are stored under tenant account. However there is additional naming convention is followed to automatically find the object associated with particular backupjobrun.
Let’s assume that tenant1 created a backup job with id “backupjob1”.
- This job has two VMs: vm1 and vm2.
- vm1 has two logical volumes: vmresource-1-1, vmresource-1-2
- vm2 has one logical volume: vmresource-2-1.
Below is how the object store will look like for particular backupjobrun with an id “backupjobrun1”
https://storage.swiftdrive.com/v1/tenant1/backupjobs is the backup jobs container.
|----backupjob1
|
|----backupjobrun1
| |
| |----vm1
| |
| |---- vmresource-1-1
| | |
| | |---- Backup
| | |
| | |---- BackupMetadata
| |
| |---- vmresource-1-2
| | |
| | |---- Backup
| | |
| | |---- BackupMetadata
|
|----vm2
| |
| |---- vmresource-2-1
| | |
| | |---- Backup
| | |
| | |---- BackupMetadata
| |
For each backup of a “vm resource” in a “backupjobrun”, an entry will be created in the Raksha database. This record contains the “url”, “metadata” and most importantly it contains a pointer “vm_resource_backup_backing_id”. For full backups this filed is ‘null’ and for an incremental backup, this points to the backing backup.
vm_resource_backups
| Id |
| backupjobrun_vm_resource_id |
| vm_resource_backup_backing_id |
| top |
| vault_service_id |
| vault_service_url |
| vault_service_metadata |
| status |
Virtualization Drivers
Virtualization drivers implement the following critical functionality
- Full Backup
- Incremental Backup
- Restore
Libvirt Driver of Raksha
This proposal includes an implementation of the driver for the QEMU using libvirt API. In order to perform full and incremental backups we will leverage the external disk snapshots functionality. External snapshots are a type of snapshots where, there’s a base image (which is the original disk image), and then its difference/delta (aka, the snapshot image) is stored in a new QCOW2 file.
For example, the following will take a live atomic external snapshot of all the volumes ( vda, vdb) attached to ‘instance-00000001’
snapshot-create-as instance-00000001 snapshot1 "First Snapshot" --disk-only --atomic
--diskspec vda,snapshot=external,file=/var/lib/libvirt/images/snap1-of-instance1-volume1-base.qcow2
--diskspec vdb,snapshot=external,file=/var/lib/libvirt/images/snap1-of-instance1-volume2-base.qcow2
Once the snapshots are taken this way, we can upload the backups to the configured vault service. What gets uploaded depends on the backup type: full or incremental
Full Backup
Below is the sequence for a full backup of ‘instance-00000001’ with a boot volume from glance and data volume from cinder.
vda: cirros-0.3.0-x86-image <-- instance-00000001-vda.qcow2 vdb: /dev/disk/by-path/cinder-volume1
Take a live, atomic external snapshot of all the volumes
vda: cirros-0.3.0-x86-image <-- instance-00000001-vda.qcow2 <-- snap1-of-vda.qcow2 vdb: /dev/disk/by-path/cinder-volume1 <-- snap1-of-vdb.qcow2
Stream the following files in to the configured vault service
cirros-0.3.0-x86-image, instance-00000001-vda.qcow2, /dev/disk/by-path/cinder-volume1
The above files constitute a full backup of the instance ‘instance-00000001’
Backup network mappings and other resources of an instance.
Issues:
- When we backup instances that share an image, there will be duplicated copies of the image. This is not very efficient usage of resources and should be addressed.
- To take the next incremental backup, we must leave the current qcow2 files (snap1-of-vda.qcow2 & snap1-of-vda.qcow2) attached to the instance. These qcow2 files (especially the data volumes) will grow in size and we need to explore ways to locate them is an appropriate place to accommodate the growth and performance requirements.
- We also need to evaluate the effect on the live migration use cases.
Incremental Backup
For incremental backup, we will start with the same configuration after a full backup or another incremental backup.
vda: cirros-0.3.0-x86-image <-- instance-00000001-vda.qcow2 <-- snap1-of-vda.qcow2 vdb: /dev/disk/by-path/cinder-volume1 <-- snap1-of-vdb.qcow2
Take a live, atomic external snapshot of all the volumes
vda: cirros-0.3.0-x86-image <-- instance-00000001-vda.qcow2 <-- snap1-of-vda.qcow2 <-- snap2-of-vda.qcow2 vdb: /dev/disk/by-path/cinder-volume1 <-- snap1-of-vdb.qcow2 <-- snap2-of-vda.qcow2
Stream the following files in to the configured vault service
- snap1-of-vda.qcow2
- snap1-of-vdb.qcow2
The above files constitute an incremental backup of the instance ‘instance-00000001’
Perform a block commit of “snap1-of-vda.qcow2” & “snap2-of-vda.qcow2”
vda: cirros-0.3.0-x86-image <-- instance-00000001-vda.qcow2 <-- snap2-of-vda.qcow2 vdb: /dev/disk/by-path/cinder-volume1 <-- snap2-of-vda.qcow2
By doing the block commit, we are reducing the qcow2 chain which is not necessary anymore. Backup network mappings and other resources of an instance.
Restore
To restore an instance from backup, we will use the following pseudo algorithm
for each resource in backupjobrun_vm_resources
download all the components of a backup to a temporary location
for each resource in backupjobrun_vm_resources
download all the components of a backup to a temporary location.
rebase the qcow2 files to the correct backing files
qemu-img rebase –b backing_file_base backing_file_top
commit and flatten the qcow2 files
qemu-img commit backing_file_top
upload images and create volumes
for a boot device, if the image doesn’t exist in glance, upload the image to glance.
for a data volume, we need to upload the backup to glance as an image and covert that to a cinder volume.
(TODO: See if Cinder can help us to create a block volume from a file instead of an image).
use nova to create a new instance
VMware Driver for Raksha
Future implementation
Hyper-V Driver for Raksha
Future implementation
Open Issues
| Issue | Status |
|---|---|
| How about providing the functionality exclude certain resources from backup job. For example a temporary space. An NFS mount etc. | Investigating |
| Any thoughts on the scheduler APIs? For example the number of concurrent jobs? | Investigating |
| Also do we need to care about where the job will run? Is that needs to be defined in the backup job or in the scheduler options? | Investigating |
| How about including some hints or metadata as key value pairs for the Swift end points? There can be some use cases for that later down the road. | Investigating |